Unix File System: Directories, Filenames and Inode

- The basics of files
- What's in a file?
- Directories and filenames
- Permissions
- Inodes
Everything in the UNIX system is a file. That is less of an over simplification than you might think. When the first version of the system was being designed, before it even had a name, the discussions focused on the structure of a file system that would be clean and easy to use. The file system is central to the success and convenience of the UNIX system. It is one of the best exams plus the "keep it simple" philosophy, shows the power achieved by the careful implementation of a few well-chosen ideas.
To talk comfortably about commands and their interrelationships, we need a good background in the structure and outer workings of the file system. This chapter covers most of the details of using the file system - what files are, how they are represented, directories and the file system hierarchy, permissions, inodes (the system's internal record of files), and device files. Avail programming assignment help for any doubts and queries that might arise while going through the blog. Because most users of the UNIX system deal with manipulating files, there are many commands for file investigation or rearrangement; this chapter introduces the more commonly used ones.
The basics of files
A file is a sequence of bytes. (A byte is a small chunk of information, typically 8 bits long. For our purposes, a byte is equivalent to a character.) No structure is imposed on a file by the system, and no meaning is attached to its contents the meaning of the bytes depends solely on the programs that interpret the file. Furthermore, as we shall see, this is true not just of disc files but of peripheral devices as well. Magnetic tapes, mail messages, characters typed on the keyboard, line 'printer output, data flowing in pipes - each of these files is just a sequence of bytes as far as the system and the programs in it are concerned. The best way to learn about files is to play with them, so start by creating a small file:
$ ed
a
now is the time
for all good people
.
w junk
36
Q
$ Is –I junk
-rw-r--r-- 1 you 36 Sep 27 06:11 junk
junk is a file with 36 bytes - the 36 characters you typed while appending (except, of course, for correction of any typing mistakes). To see the file,
$ cat junk
now is the time
for all good people
$
cat shows what the file looks like. The command od (octal dump) prints a Lesvisible representation of all the bytes of a file:
$ od –c junk
0000000 now is the time
0000020 for all good people
0000040 ple \n
0000044
$
The -c option means "interpret bytes as characters." Turning on the -b option will show the bytes as octal (base 8) numbers as well:
$ od –cb junk
0000000 now is the time
156 157 167 040 151 163 040 164 150 145 040 164 151 155 145 012
0000020 for all good people
146 157 162 040 141 154 154 040 147 157 144 040 160 145 157
0000040 plan \n
160 154 145 012
0000044
$
The 7-digit numbers down the left side are positions in the file, that is, the ordinal number of the next character shown, in octal. By the way, the emphasis on octal numbers is a holdover from the PDP-11, for
which octal was the preferred notation. Hexadecimal is better suited for other machines; the -x option tells od to print in hex. Notice that there is a character after each line, with an octal value of 012. This is the ASCII newline character; it is what the system places in the input when you press the RETURN key. By a convention borrowed from C, the character representation of a newline is n, but this is only a convention used by programs like od to make it easy to read -the value stored in the file is the single byte 012.
Newline is the most common example of a special character. Other characters associated with some terminal control operation include backspace (octal value 010, printed as \b), tab (011, \t), and carriage return (0.15, \r). It is important in each case to distinguish between how the character is stored in a file and how it is interpreted in various situations. For example, when you type a backspace on your keyboard (and assuming that your erase character is backspace), the kernel interprets it to mean that you want to discard whatever character you typed previously. Both that character and the backspace disappear, but the backspace is echoed to your terminal, where it makes the cursor move one position backward. If you type the sequence (i.c., followed by a backspace), however, the kernel interprets that to mean that you want a literal backspace in your input, so the is discarded and the byte 010 winds up in your file. When the backspace is echoed on your terminal, it moves the cursor to sit on top of the \.
When you print a file that contains a backspace, the backspace is passed uninterpreted to your terminal, which again will move the cursor one position backward. When you use od to display a file that contains a backspace, it appears as a byte with value 010, or, with the -c option, as \b.
The story for tabs is much the same: on input, a tab character is echoed to your terminal and sent to the program that is reading; on output, the tab is simply sent to the terminal for interpretation there. There is a difference, though you can tell the kernel that you want it to interpret tabs for you on output; in that case, each tab that would be printed is replaced by the right number of blanks to get to the next tab stop. Tab stops are set at columns 9. 17, 25, etc. The command
$ stty -tabs
causes tabs to be replaced by spaces when printed on your terminal. See stty(1). The treatment of RETURN is analogous. The kernel echoes RETURN as a carriage return and a newline, but stores only the newline in the input. On output, the newline is expanded into carriage return and newline. The UNIX system is unusual in its approach to representing control Informa on, particularly its use of newlines to terminate lines. Many systems instead provide "records," one per line, each of which contains not only your data but also a count of the number of characters in the line (and no new line). Other systems terminate each line with a carriage return and a newline because that sequence is necessary for output on most terminals. (The word "linefeed" is a synonym for newline, so this sequence is often called "CRLF." which is nearly pronounceable.)
The UNIX system does neither there are no records, no record counts, and no bytes in any file that you or your programs did not put there. A new line is expanded into a carriage return and a new line when sent to a terminal. but programs need only deal with the single newline character because that is all they see. For most purposes, this simple scheme is exactly what is wanted. When a more complicated
the structure is needed, it can easily be built on top of this; the converse, creating simplicity from complexity, is harder to achieve.
Since the end of a line is marked by a newline character, you might expect a file to be terminated by another special character, say \e for "end of the file." Looking at the output of od, though, you will see no special character at the end of the file it just stops. Rather than using a special code, the system signifies the end of a file by simply saying there is no more data in the file. The kernel keeps track of file lengths, so a program encounters end-of-file when it has processed all the bytes in a file.Programs retrieve the data in a file by a system call (a subroutine in the kernel) called read. Each time read is called, it returns the next part of a file the next line of text typed on the terminal, for example. read also says how many bytes of the file was returned, so the end of the file is assumed when a reader says "zero bytes are being returned." If there were any bytes left, read would have returned some of them. It makes sense not to represent the end of the file by a special byte value, because, as we said earlier, the meaning of the bytes depends on the interpretation of the file. But all files must end, and since all files must be accessed through reading, returning zero is an interpretation-independent way to represent the end of a file without introducing a new special character.
When a program reads from your terminal, each input line is given to the program by the kernel only when you type its newline (i.e, press RETURN). Therefore if you make a typing mistake, you can back up and correct it if you realize the mistake before you type newline. If you type newline before realizing the error, the line has been read by the system and you cannot correct it. We can see how this line-at-a-time input works using a cat. a cat normally saves up or buffers its output to write in large chunks for efficiency, but the cat -u "unbuffered" the output, so it is printed immediately as 'it is read:
$ cat Buffered output from cat
123
456
789
Ctrl-d
123
456
789
$ cat –u
123
123
456
456
789
789
Ctrl-d
$
cat receives each line when you press RETURN; without buffering, it prints the data as it is received. Now try something different: type some characters and then a CTL-d rather than a RETURN:
$ cat –u
123ctl-d123
cat prints the characters out immediately. Cecil-d says, "immediately send the characters I have typed to the program that is reading from my terminal." The card itself is not sent to the program, unlike a newline. Now type a second ctl-d, with no other characters:
$ cat -u
123ctl-d123ctl-d$
The shell responds with a prompt, because the cat read no characters, decided that meant end of file, and stopped. ctl-d sends whatever you have typed to the program that is reading from the terminal. If you haven't typed anything, the program will therefore read no characters, and that looks like the end of the file. That is why typing ctl-d logs you out - the shell sees no more input. Of course, Cecil-d is usually used to signal an end-of-file but, interestingly, it has a more general function.
Exercise 2-1.What happens when you type crl-d to ed? Compare this to the command
$ ed
What's in a file?
The format of a file is determined by the programs that use it; there is a wide variety of file types, perhaps because there is a wide variety of programs. But since file types are not determined by the file system, the kernel can't tell you the type of a file: it doesn't know it. The file command makes an educated guess (we'll explain how shortly):
$ file /bin/bin/ed /usr/src/cmd/ed.c /usr/man/man1/ed. 1
/bin: directory
/bin/ed: pure executable
/usr/src/cmd/ed.c: c program text
/usr/man/man1/ed. 1: roff, off, or eqn input text
These are four fairly typical files, all related to the editor: the directory in which it resides (/bin), the "binary" or runnable program itself (/bin/ed), the "source" or C statements that define the program (/usr/src/cmd/ed.c) and the manual page (/usr/man/man1/ed. 1).
To determine the types, file didn't pay attention to the names (although it I could have), because naming conventions are just conventions, and thus not perfectly reliable. For example, files suffixed .c are almost always C source, but there is nothing to prevent you from creating a .c file with arbitrary con tents. Instead, file reads the first few hundred bytes of a file and looks for clues to the file type. (As we will show later on, files with special system pro perties, such as directories, can be identified by asking the system, but file could identify a directory by reading it.)
Sometimes the clues are obvious. A runnable program is marked by a binary "magic number" at its beginning. od with no options dumps the file in
16-bit, or 2-byte, words and makes the magic number visible:
$ od /bin/ed
0000000 000410 025000 000462 011444 000000 000000 000000 000001
0000020 170011 016600 000002 005060 177776 010600 162706 000004
0000040 016616 000004 005720 010066 000002 005720 001376 020076
The octal value 410 marks a pure executable program, one for which the exe cuting code may be shared by several processes. (Specific magic numbers are system dependent.) The bit pattern represented by 410 is not ASCII text, so this value could not be created inadvertently by a program like an editor. But you could certainly create such a file by running a program of your own, and the system understands the convention that such files are program binaries.
For text files, the clues may be deeper in the file, so file looks for words like #include to identify C source, or lines beginning with a period to iden tify nroff or troff input.
You might wonder why the system doesn't track file types more carefully, so that, for example, sort is never given /bin/ed as input. One reason is to avoid foreclosing some useful computation. Although
$ sort /bin/ed
doesn't make much sense, there are many commands that can operate on any file at all, and there's no reason to restrict their capabilities. od, wc, cp, cmp. file and many others process files regardless of their contents. But the for matless idea goes deeper than that. If, say, nroff input were distinguished from C source, the editor would be forced to make the distinction when it created a file, and probably when it read in a file for editing again. And it would certainly make it harder for us to typeset the C programs in Chapters 6 through 8!
Instead of creating distinctions, the UNIX system tries to efface them. All text consists of lines terminated by newline characters, and most programs understand this simple format. Many times while writing this book, we ran commands to create text files, processed them with commands like those listed above, and used an editor to merge them into the troff input for the book. The transcripts you see on almost every page are made by commands like
$ od -c junk >temp
$ ed ch2.1
1534
r temp
168
…
od produces text on its standard output, which can then be used anywhere text can be used. This uniformity is unusual; most systems have several file formats, even for text, and require negotiation by a program or a user to create a file of a particular type. In UNIX systems there is just one kind of file, and all that is required to access a file is its name.
The lack of file formats is an advantage overall programmers needn't worry about file types, and all the standard programs will work on any file - but there are a handful of drawbacks. Programs that sort and search and edit expect text as input: grep can't examine binary files correctly, nor can sort them, nor can any standard editor manipulate them.
There are implementation limitations with most programs that expect text as input. We tested some programs on a 30,000-byte text file containing no newlines, and surprisingly few behaved properly because most programs make unadvertised assumptions about the maximum length of a line of text (for an exception, see the BUGS section of sort(1)).
Non-text files have their place. For example, very large databases usually need extra address information for rapid access; this has to be binary for efficiency. But every file format that is not text must have its own family of support programs to do things that the standard tools could perform if the format were text. Text files may be a little less efficient in machine cycles, but this must be balanced against the cost of extra software to maintain more specialized formats. If you design a file format, you should think carefully before choosing a non-textual representation. (You should also think about making your programs robust in the face of long input lines.)
Directories and filenames
All the files you own have unambiguous names, starting with /usr/you, but if the only file you have is junk, and you type 1s, it doesn't print /usr/you/junk; the filename is printed without any prefix:
$ Is junk
/usr/you
$
That is because each running program, that is, each process, has a current directory, and all filenames are implicitly assumed to start with the name of that directory unless they begin directly with a slash. Your login shell, and 1s, therefore have a current directory. The command PWD (print working directory) identifies the current directory:
$ PWD
/usr/you
$
The current directory is an attribute of a process, not a person or a program people have login directories, and processes have current directories. If a process creates a child process, the child inherits the current directory of its parent. But if the child then changes to a new directory, the parent is unsafe fected its current directory remains the same no matter what the child does.
The notion of a current directory is certainly a notational convenience because it can save a lot of typing, but its real purpose is organizational. Related files belong together in the same directory. /usr is often the top directory of the user file system. (user is abbreviated to usr in the same spirit as CMP, 1s, etc.) /usr/you are your login directory, your current directory when you first log in. /usr/src contains source for system programs, /usr/src/cmd contains source for UNIX commands, /usr/src/cmd/sh contains the source files for the shell, and so on. Whenever you embark on a new project, or whenever you have a set of related files, say a set of recipes, you could create a new directory with mkdir and put the files there.
$ PWD
/usr/you
$ mkdir recipes
$ cd recipes
$ PWD
/usr/you/recipes
$ mkdir pie cookie
$ ed pie/apple.
$ ed cookie/chocochip
…
$
Notice that it is simple to refer to subdirectories. pie/apple has an obvious meaning: the apple pie recipe, in directory /usr/you/recipes/pie. You could instead have put the recipe in, say, recipes/apple.pie, rather than in a subdirectory of recipes, but it seems better organized to put all the pies together, too. For example, the crust recipe could be kept in recipes/pie/crust rather than duplicated in each pie recipe. Although the file system is a powerful organizational tool, you can forget where you put a file, or even what files you've got. The obvious solution is a command or two to rummage around in directories. The 1s command is certainly helpful for finding files, but it doesn't look in sub-directories.
$ cd
$ Is
junk
recipes
$file *
junk: ASCII text
recipes: directory
$ Is recipes
Cookie
Pie
$ is recipes/pie
apple
crust
$
This piece of the file system can be shown pictorially as:
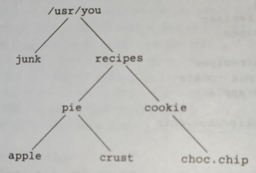 The command du (disk usage) was written to tell how much disc space is consumed by the files in a directory, including all its subdirectories.
The command du (disk usage) was written to tell how much disc space is consumed by the files in a directory, including all its subdirectories.
$ du
6 ./recipes/pie
4 ./recipes/cookie
11 ./recipes
13.
The filenames are obvious; the numbers are the number of discs blocks-typically 512 or 1024 bytes each of storage for each file. The value for a directory indicates how many blocks are consumed by all the files in that directory and its subdirectories, including the directory itself. du has an option -a, for "all," that causes it to print out all the files in a directory. If one of those is a directory, du processes that as well:
$ du -a
2 ./recipes/pie/apple
3 ./recipes/pie/crust
6 ./recipes/pie
3 ./recipes/cookie/choco chip
4 ./recipes/cookie
11 ./recipes
1 ./junk
13.
$
The output of du -a can be piped through grep to look for specific files:
$ du –a | grep choc
3 ./recipes/cookie/choco chip
$
Recall from Chapter 1 that the name '.' is a directory entry that refers to the directory itself; it permits access to a directory without having to know the full name. du looks in a directory for files; if you don't tell it which directory, it assumes., the directory you are in now. Therefore, junk and ./junk are names for the same file.
Despite their fundamental properties inside the kernel, directories sit in the file system as ordinary files. They can be read as ordinary files. But they can't be created or written as ordinary files to preserve their sanity and the users' files, the kernel reserves to itself all control over the contents of directories.
The time has come to look at the bytes in a directory:
$ od -cb.
0000000 4 ; . \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
064 073 056 000 000 000 000 000 000 000 000 000 000 000 000 000
0000020 273 ( . . \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
273 050 056 056 000 000 000 000 000 000 000 000 000 000 000
0000040 252 ; r e c i p e s \0 \0 \0 \0 \0 \0 \0 \0
252 073 162 145 143 151 160 145 163 000 000 000 000 000 000
0000060 230 = j u n k \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
230 075 152 165 156 153 000 000 000 000 000 000 000 000 000
0000100
$
See the filenames buried in there? The directory format is a combination of binary and textual data. A directory consists of 16-byte chunks, the last 14 bytes of which hold the filename, padded with ASCII NULs (which have value 0), and the first two of which tell the system where the administrative information for the file resides we'll come back to that. Every directory begins with two entries.("dot") and .. ("dot-dot").
$ cd Home
$ cd recipes
$ PWD
/usr/you/recipes
$ cd ..; PWD Up one level
/usr/you
$ cd ..; PWD Up another level
/usr
$ cd ..; PWD Up another level
/
$ cd ..; PWD Up another level
/ Can't go any higher
$
The directory is called the root of the file system. Every file in the system is in the root directory or one of its subdirectories, and the root is its parent directory.
Exercise 2-2. Given the information in this section, you should be able to understand roughly how the 1s command operates. Hint: cat. >foo; ls -f foo.
Exercise 2-3. (Harder) How does the PWD command operate? an Exercise 2-4. du was written to monitor disc usage. Using it to find files in a directory hierarchy is at best a strange idiom, and perhaps inappropriate. As an alternative, look at the manual page to find(1) and compare the two commands. In particular, compare the command du -a 1 grep... with the corresponding invocation of find. Which runs faster? Is it better to build a new tool or use a side effect of an old one?
Permissions
Every file has a set of permissions associated with it, which determine who can do what with the file. If you're so organized that you keep your love letters on the system, perhaps hierarchically arranged in a directory, you probably don't want other people to be able to read them. You could therefore change the permissions on each letter to frustrate gossip (or only on some of the letters, to encourage it), or you might just change the permissions on the directory containing the letters, and thwart snoopers that way.
But we must warn you: there is a special user on every UNIX system, called the super-user, who can read or modify any file on the system. The special login name root carries super-user privileges; it is used by system administrators when they do system maintenance. There is also a command called so that grants super-user status if you know the root password. Thus anyone who knows the super-user password can read your love letters, so don't keep sensitive material in the file system. If you need more privacy, you can change the data in a file so that even the super-user cannot read (or at least understand) it, using the crypt command (crypt(1)). Of course, even a crypt isn't perfectly secure. A super-user can change the crypt command itself, and there are cryptographic attacks on the crypt algorithm. The former requires malfeasance and the latter takes hard work, however, so crypt is in practice fairly secure. In real life, most security breaches are due to passwords that are given away or easily guessed. Occasionally, system administrative lapses make it possible for a malicious user to gain super-user permission. Security issues are discussed further in some of the papers cited in the bibliography at the end of this chapter. When you log in, you type a name and then verify that you" are that person by typing a password. The name is your login identification or login-id. But the system recognizes you by a number, called your user-id, or uid. Different login ids may have the same uid, making them indistinguishable from the system, although that is relatively rare and perhaps undesirable for security reasons. Besides a uid, you are assigned a group identification, or group id, which places you in a class of users. On many systems, all ordinary users (as opposed to those with login IDs like root) are placed in a single group called the other, but your system may be different. The file system, and therefore the UNIX system in general, determines what you can do by the
permissions granted to your uid and group-id. The file /etc/password is the password file; it contains all the login information about each user. You can discover your uid and group-id, as does the system, by looking up your name in /etc/passwd:
$grep you /etc/passwd
The fields in the password file are separated by colons and are laid out like this (as seen in passwd(5)):
login-id: encrypted-password: uid: group-id: miscellany: login-directory: shell
The file is ordinary text, but the field definitions and separator are a convention agreed upon by the programs that use the information in the file. The shell field is often empty, implying that you use the default shell, /bin/sh. The miscellany field may contain anything; often, it has your name and address or phone number.
Note that your password appears here in the second field, but only in an encrypted form. Anybody can read the password file (you just did), so if your password itself were there, anyone would be able to use it to masquerade as you. When you give your password to log in, it encrypts it and compares the result against the encrypted password in /etc/passwd. If they agree, it lets you log in. The mechanism works because the encryption algorithm has the property that it's easy to go from the clear form to the encrypted form, but very hard to go backward. For example, if your password is ka-boom, it might be encrypted as gkmbCTrJ04COM, but given the latter, there's no easy way to get back to the original.
The kernel decided that you should be allowed to read /etc/passwd by looking at the permissions associated with the file. There are three kinds of permissions for each file: read (i.e., examine its contents), write (i.e., change its contents), and execute (i.e., run it as a program). Furthermore, different permissions can apply to different people. As file owner, you have one set of reading, writing, and executing permissions. Your "group" has a separate set. Everyone else has a third set.
The 1 option of 1s prints the permissions information, among other things:
$ ls -1 /etc/passwd
-rw-r--r-- 1 root 5115 Aug 30 10:40 /etc/passwd
$ ls -LG /etc/passwd
-rw-r--r-- 1 adm 5115 Aug 30 10:40 /etc/passwd
These two lines may be collectively interpreted as: /etc/passwd is owned by login-id root, group adm is 5115 bytes long, was last modified on August 30 at 10:40 AM, and has one link (one name in the file system; we'll discuss links in the next section). Some versions of 1s give both owner and group in one invocation.
The string -rw-r--r-- is how 18 represents the permissions on the file. The first indicates that it is an ordinary file. If it were a directory, there would be a d there. The next three characters encode the file owner's (based on uid) read, write and execute permissions. rw- means that root (the owner) may read or write, but not execute the file. An executable file would have an x instead of a dash. The next three characters (x--) encode group permissions, in this case, so that people in group adm, presumably the system administrators, can read the file but not write or execute it. The next three (also r--) define the permissions for everyone else and the rest of the users on the system. On this machine, then, only the root can change the login information for a user, but anybody may read the file to discover the information. A plausible alternative would be for group adm to also have written permission on /etc/passwd.
The file /etc/group encodes group names and groups and defines which users are in which groups. /etc/passwd identifies only your login group; the newgrp command changes your group permissions to another group.
Anybody can say
$ ed /etc/passwd
and edit the password file, but only the root can write back the changes. You might therefore wonder how you can change your password since that involves editing the password file. The program to change passwords is called passwd; you will probably find it in /bin:
$ Is-1/bin/passwd
-rwar-xr-x 1 root 8454 Jan 4 1983 /bin/passwd
$
(Note that /etc/passwd is the text file containing the login information, while /bin/passwd, in a different directory, is a file containing an executable program that lets you change the password information.) The permissions here state that anyone may execute the command, but only the root can change the passwd command. But the s instead of an x in the execute field for the file owner states that, when the command is run, it is to be given the permissions corresponding to the file owner, in this case, root. Because /bin/passwd is "set-uid" to root, any user can run the passwd command to edit the password file. The set-uid bit is a simple but elegant idea that solves some security problems. For example, the author of a game program can make the program set-uid to the owner, so that it can update a score file that is otherwise protected from other users' access. But the set-uid concept is potentially dangerous. /bin/passwd has to be correct; if it were not, it could destroy system information under the root's auspices. If it had the permissions -rwarwxrwx, it could be overwritten by any user, who could therefore replace the file with a program that does anything. This is particularly serious for a set-uid program because the root has access permissions to every file on the system. (Some UNIX systems turn the set-uid bit off whenever a file is modified, to reduce the danger of a security hole.)
The set-uid bit is powerful but used primarily for a few system programs such as passwd. Let's look at a more ordinary file.
$Is -I /bin/who
$
who is executable by everybody, and writable by root and the owner's group. What "executable" means is this: when you type
$ who
to the shell, it looks like a set of directories, one of which is /bin, for a file named "who." If it finds such a file, and if the file has to execute permission, the shell calls the kernel to run it. The kernel checks the permissions, and, if they are valid, runs the program. Note that a program is just a file with execute permission. In the next chapter, we will show you programs that are just text files, but that can be executed as commands because they have to execute permission set.
Directory permissions operate a little differently, but the basic idea is the same.
$ ls -ld.
drwxrwxr-x 3 you 08 Sep 27 06:11.
$
The -d option of 1s asks it to tell you about the directory itself, rather than its contents, and the leading d in the output signifies that '.' is indeed a directory. Anr field means that you can read the directory, so you can find out what files are in it with 1s (or od, for that matter). A w means that you can create and delete files in this directory because that requires modifying and therefore writing the directory file.
You cannot simply write in a directory even root is forbidden to do so.
$ who >. Try to overwrite "."
.: cannot create You can't
$
Instead, there are system calls that create and remove files, and only through them is it possible to change the contents of a directory. The permissions idea, however, still applies: the w fields tell who can use the system routines to modify the directory.
Permission to remove a file is independent of the file itself. If you have to write permission in a directory, you may remove files there, even files that are protected against writing. The rm command asks for confirmation before removing a protected file, however, to check that you want to do so one of the rare occasions that a UNIX program double-checks your intentions. (The -f flag to rm forces it to remove files without question.).
The x field in the permissions on a directory does not mean execution; it means "search." Executing permission on a directory determines whether the directory may be searched for a file. It is, therefore, possible to create a directory with mode --x for other users, implying that users may access any file that they know about in that directory, but may not run it on it or read it to see what files are there. Similarly, with directory permissions --, users can see (1s) but not use the contents of a directory. Some installations use this device to turn off /usr/games during busy hours. The chmod (change mode) command changes permissions on files.
chmod permissions filenames...
The syntax of the permissions is clumsy, however. They can be specified in two ways, either as octal numbers or by symbolic description. The octal numbers are easier to use, although the symbolic descriptions are sometimes convenient because they can specify relative changes in the permissions. It would be nice if you could say
$ chmod rw-rw-rw- junk Doesn't work this way!
rather than
$ chmod 666 junk
but you cannot. The octal modes are specified by adding together a 4 for reading, 2 for writing, and 1 for executing permission. The three digits specify, as in 1s, permissions for the owner, group, and everyone else. The symbolic codes are difficult to explain; you must look in chmod(1) for a proper description. For our purposes, it is sufficient to note that turns permission on and that - turns it off. For example,
$ chmod +x command
allows everyone to execute the command, and
$ chmod -w file
turns off write permission for everyone, including the file's owner. Except for the usual disclaimer about super-users, only the owner of a file may change the permissions on a file, regardless of the permissions themselves. Even if somebody else allows you to write a file, the system will not allow you to change its permission bits.
$ Is –Id /usr/mary
drwxrwxrwx 5 mary 704 Sep 25 10:18 /usr/mary
$ chmod 444 /usr/mary
Chmod : can’t change /usr/mary
$
If a directory is writable, however, people can remove files in it regardless of the permissions on the files themselves. If you want to make sure that you or your friends never delete files from a directory, remove write permission from it:
$ cd
$ date >temp
$ chmod –w Make directory unwritable
$ Is –Id.
dr-xr-xr-x 3 you 08 Sep 27 11:48.
$ rm temp
Rm: temp not removed Can’t remove file
$ chmod 775 Restore permission
$ Is –Id.
Drwxrwxr-x 3 you 08 Sep 27 11:48.
$ Now you can
The temp is now gone. Notice that changing the permissions on the directory didn't change its modification date. The modification date reflects changes to the file's contents, not its modes. The permissions and dates are not stored in the file itself, but in a system, a structure called an index node, or i-node, is the subject of the next section.
Exercise 2-5. Experiment with chmod. Try different simple modes, like 0 and 1. Be careful not to damage your login directory!
Inodes
A file has several components: a name, contents, and administrative information such as permissions and modification times. The administrative information is stored in the inode (over the years, the hyphen fell out of "i-node"). along with essential system data such as how long it is, where on the disc the contents of the file are stored, and so on.
There are three times in the inode: the time that the contents of the file were last modified (written); the time that the file was last used (read or executed); and the time that the inode itself was last changed, for example, to set the permissions.
$ date
Tue Sep 27 12:07:24 EDT 1983
$date >junk
$Is –I junk
-rw-rw-rw- 1 you 29 Sep 27 12:07 junk
$Is – Iu junk
-rw-rw-rw- 1 you 29 Sep 27 06:11 junk
$ Is – Ic junk
-rw-rw-rw- 1 you 29 Sep 27 12:07 junk
$
Changing the contents of a file does not affect its usage time, as reported by 18 -lu, and changing the permissions affects only the inode change time, as reported by ls -lc.
$ chmod 444 junk
$ ls -lu junk
-r--r--r-- 1 you 29 Sep 27 06:11 junk
$ ls -lc junk
-r--r--r-- 1 you 29 Sep 27 12:11 junk
$ chmod 666 junk
$
The -t option to 1s, which sorts the files according to time, by default that of the last modification, can be combined with -c or -u to report the order in which inodes were changed or files were read:
$ ls recipes
cookie
pie
$ ls -out
total 2
drwxrwxrwx 4 you 64 Sep 27 12:11 recipes
-rw-rw-rw- 1 you 29 Sep 27 06:11 junk
recipes are most recently used because we just looked at their contents. It is important to understand inodes, not only to appreciate the options on 1s but because in a strong sense the inodes are the files. All the directory hierarchy does is provide convenient names for files. The system's internal name for a file is its i-number: the number of the inode holding the file's information. 1s I reports the i-number in decimal:
$ date >x
$ ls -i
15768 junk
15274 recipes
15852 x
It is the i-number that is stored in the first two bytes of a directory, before the name. od -d will dump the data in decimal by byte pairs rather than octal by bytes and thus make the i-number visible.
$ od –c
0000000 4 ; . \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
0000020 273 ( . . \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
0000040 252 ; r e c i p e s \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
0000060 230 = j u n k \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
0000100 354 = x \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
0000120
$ od –d
0000000 15156 00046 00000 00000 00000 00000 00000 00000
0000020 10427 11822 00000 00000 00000 00000 00000 00000
0000040 15274 25970 26979 25968 00115 00000 00000 00000
0000060 15768 30058 27508 00000 00000 00000 00000 00000
0000100 15852 00120 00000 00000 00000 00000 00000 00000
0000120
$
The first two bytes in each directory entry are the only connection between the name of a file and its contents. A filename in a directory is therefore called a link, because it links a name in the directory hierarchy to the inode, and hence to the data. The same i-number can appear in more than one directory. The rm command does not remove inodes; it removes directory entries or links. Only when the last link to a file disappears does the system remove the inode, and hence the file itself.
If the i-number in a directory entry is zero, it means that the link has been removed, but not necessarily the contents of the file there may still be a link somewhere else. You can verify that the i-number goes to zero by removing the file:
$ rm x
$od –d
0000000 15156 00046 00000 00000 00000 00000 00000 00000
0000020 10427 11822 00000 00000 00000 00000 00000 00000
0000040 15274 25970 26979 25968 00115 00000 00000 00000
0000060 15768 30058 27502 00000 00000 00000 00000 00000
0000100 00000 00120 00000 00000 00000 00000 00000 00000
0000120
$
The next file created in this directory will go into the unused slot, although it will probably have a different i-number. The in-command links to an existing file, with the syntax
$ in old-file new-file
The purpose of a link is to give two names to the same file, often so it can appear in two different directories. On many systems, there is a link to /bin/ed called /bin/e, so that people can call the editor e. Two links to a file point to the same inode, and hence have the same i-number:
In junk linktojunk
$ Is -li
total 3
15768 -rw-rw-rv- 2 you 29 Sep 27 12:07 Junk
15768 -rw-rw-rv- 2 you 29 Sep 27 12:07 linktojunk
15274 drwxrwxrwx 4 you 64 Sep 27 09:34 recipes
The integer printed between the permissions and the owner is the number of links to the file. Because each link just points to the inode, each link is equally important there is no difference between the first link and subsequent ones. (Notice that the total disc space computed by 18 is wrong because of double counting.)
When you change a file, access to the file by any of its names will reveal the changes, since all the links point to the same file.
$ echo x > junk
$ Is -I
total 3
-rw-rw-rw- 2 you 2 Sep 27 12:37 junk
-rw-rw-rw- 2 you 2 Sep 27 12:37 junk
Drwxrwxrwx 4 you 64 Sep 27 09:34 recipes
$ rm linktojunk
$ Is –I
Total
-rw-rw-rw- 1 you 2 Sep 27 12:37 junk
Drwxrwxrwx 4 you 64 Sep 27 09:34 recipes
$
After 1inktojunk is removed the link count goes back to one. As we said before, arming a file just breaks a link; the file remains until the last link is removed. In practice, of course, most files only have one link, but again we see a simple idea providing great flexibility.
A word to the hasty: once the last link to a file is gone, the data is irretrievable. Deleted files go into the incinerator, rather than the waste basket, and there is no way to call them back from the ashes. (There is a faint hope of resurrection. Most large UNIX systems have a formal backup procedure that periodically copies changed files to some safe place like magnetic tape, from which they can be retrieved. For your protection and peace of mind, you should know just how much backup is provided on your system. If there is none, watch out some mishap to the discs could be a catastrophe.)
Links to files are handy when two people wish to share a file, but sometimes you want a separate copy of a different file with the same information. You might copy a document before making extensive changes to it, for example, so you can restore the original if you decide you don't like the changes. Linking wouldn't help, because when the data changed, both links would reflect the change, or makes copies of files:
$ cp junk copy junk
$ Is –li
Total 3
15850 –rw –rw-rw- 1 you 2 Sep 27 13:13 copy junk
15768 –rw-rw-rw- 1 you 3 Sep 27 12:37 junk
15274 drwxrwxrwx 4 you 64 Sep 27 09:34 recipes
$
The i-numbers of junk and copy of junk are different, because they are different files, even though they currently have the same contents. It's often a good idea to change the permissions on a backup copy so it's harder to remove it accidentally.
$ chmod -w copy of junk Turn off write permission
$ ls -li
total 3
15850 -r--r--r-- 1 you 2 Sep 27 13:13 copy of junk
15768 -rw-rw-rw- 1 you 2 Sep 27 12:37 junk
15274 drwxrwxrwx 4 you 64 Sep 27 09:34 recipes
rm: copyof junk 444 mode n No! It's precious
$ date> junk
$ ls -li
total 3
15850 -r--r--r-- 1 you 2 Sep 27 13:13 copy of junk
15768 -rw-rw-rw- 1 you 29 Sep 27 13:16 junk
15274 drwxrwxrwx 4 you 64 Sep 27 09:34 recipes
$ rm copy of junk
rm: copy of junk 444 mode y Well, maybe not so precious
$ ls –li
total 2
15768 -rw-rw-rw- 1 you 29 Sep 27 13:16 junk
15274 drwxrwxrwx 4 you 64 Sep 27 09:34 recipes
$